Swiss PGDay 2025
Thursday, 26 June and Friday, 27 June 2025
OST Eastern Switzerland University of Applied Sciences, Campus Rapperswil (Switzerland)
This conference is all about PostgreSQL - the world's most advanced open source database.
Take the opportunity to meet with other people interested in PostgreSQL in Switzerland.
This year's Swiss PGDay will last two days with two tracks of
presentations,
presentations,
in English and German. At least one of the presentations will be in English at all times. At the end of the first day (Thursday),
all participants are invited to a networking event
to enjoy networking and personal exchange. The conference is suitable for everyone,
from novices to experts and from back office staff to decision makers.
There will also be a poster exhibition and lightning talks where participants can share their projects, ideas and use cases.
Do you have any questions or comments? Please email us at:
info@pgday.ch.
We are looking forward to welcome you!
The organizing committee
 The Swiss PGDay is organized by the
Swiss PostgreSQL Users Group (SwissPUG)
The Swiss PGDay is organized by the
Swiss PostgreSQL Users Group (SwissPUG)
|
English Sessions |
German Sessions |
|
| Thursday, 26.06.2025 |
| Time |
Room 3.008 |
Room 3.010 |
| 08:15 - 08:55 |
Registration / Coffee - Cafeteria in building 8 |
| 08:55 - 09:10 |
Welcome: Stefan Keller - Room 3.008

Stefan Keller, OST
Professor for information systems, founder and head of Geometa Labs. Keller is a member of the Swiss PGDay board and involved in various open source projects such as PostGIS and QGIS and open data initiatives, e.g. OpenStreetMap. Besides, he is generally interested in geographic data and their visualization as well as in the the integration of open source and proprietary solutions (e.g. QGIS and ArcGIS).
Professor für Informationssysteme sowie Leiter und Gründer des Geometa Labs. Ist u.a. Mitglied des Swiss PGDay OK und engagiert in verschiedenen Open Source Projekten (z.B. PostGIS und QGIS) und Open Data (v.a. OpenStreetMap). Zudem interessieren ihn allgemein Geodaten und Geovisualisierung sowie die Integration von Open Source und proprietärer Software (z.B. QGIS und ArcGIS).
Slides
|
| 09:10 - 10:00 |
Keynote: Bruce Momjian, How Open Source and Democracy Drive Postgres - Room 3.008

Bruce Momjian, EDB
How Open Source and Democracy Drive Postgres
How does open source work? Why is it so efficient? How do democratic principles enter into the development process?
The first half of the talk explains how open source software differs from proprietary and the open source software life cycle.
The second half of the talk covers the history of various governing structures and why democracy provides superior results.
It then explains that open source is a form of democracy. It also covers the many benefits Postgres has enjoyed using an open
development model, and how its future remains bright.
Target audience: General, Level: Beginner
Bruce Momjian is co-founder and core team member of the PostgreSQL Global Development Group, and has worked on PostgreSQL since 1996.
He has been employed by EnterpriseDB since 2006. He has spoken at many international open-source conferences and is the author of PostgreSQL:
Introduction and Concepts, published by Addison-Wesley. Prior to his involvement with PostgreSQL, Bruce worked as a consultant, developing
custom database applications for some of the world's largest law firms. As an academic, Bruce holds a Masters in Education, was a high school
computer science teacher, and lectures internationally at universities.
Slides
Part 1
Part 2
|
| 10:00 - 10:20 |
Break - Cafeteria in building 8 |
| 10:20 - 11:10 |
Gulcin Yildirim Jelinek, Anatomy of Table-Level Locks in PostgreSQL

Gulcin Yildirim Jelinek, Xata
Anatomy of Table-Level Locks in PostgreSQL
Understanding table-level locks in Postgres is a quite useful skill as almost all DDL operations require acquiring one of the
different types of table-level locks on the object being manipulated. If not managed well, schema changes can result in downtime. In this talk
we will explain fundamentals of table-level locking, covering how different types of locks are applied and queued during schema changes.
Attendees will learn how to identify and manage lock conflicts to minimize downtime, avoid deadlocks, and maintain smooth database operations,
even during high-concurrency schema changes.
Target audience: General, Level: Intermediate
Gülçin started working with Postgres at a startup company in 2012 and was amazed at how powerful Postgres truly is! Over the years, she has
actively contributed to the PostgreSQL community by organizing conferences, delivering talks, and engaging as a dedicated community member. In
recognition of her commitment, Gülçin was elected to the PostgreSQL Europe Board in 2017.
Fueled by her passion for PostgreSQL automation and cloud technologies, Gülçin took on the role of Cloud Services Manager and led the cloud
development efforts at 2ndQuadrant, which was later acquired by EDB in 2020. Committed to fostering diversity and inclusion, she is an integral
part of Postgres Women, advocating for increased representation of women in technical communities.
Currently, Gülçin is a Staff Database Engineer at Xata, where she continues to explore her interests in PostgreSQL. In addition to her engineering
work, she is one of the co-founders of Kadin Yazilimci (Women Developers of Turkey) and has led the core team for more than 10 years. In 2023,
she launched Diva: Dive into AI Conference as a Kadin Yazilimci initiative and has been part of the organizing team since.
She is an active member of Postgres community, hoping to contribute to the longevity and health of the Postgres project. Gülçin lives in Prague
and is the co-founder and organizer of the monthly Prague PostgreSQL Meetup for over 7 years.
Slides
|
Laurenz Albe, Mach das nicht!

Laurenz Albe, CYBERTEC
Mach das nicht!
Im Lauf der Jahre sind mir bei der Beschäftigung mit Datenmodellen und den daraus entstehenden Problemen etliche Muster begegnet, die sich als
durchwegs schlecht erwiesen haben. Der Vortrag erklärt, was die Probleme sind. So kann man bekannte Fallen vermeiden.
Themen:
- als Datentyp String verwenden, obwohl es einen dedizierten Datentyp gäbe
- 4 Byte Integer als automatisch generierter Schlüssel
- "varchar" statt "text" verwenden
- NULL in allen Spalten zulassen
- Large Objects
- ENUM-Datentypen falsch verwenden
- gefährliche Check-Constraints
- lügen uber IMMUTABLE
- Entity-Attribute-Value Design
Target audience: Developer, Level: Beginner
PostgreSQL contributor, senior database engineer and maintainer of oracle_fdw and pgreplay
Slides
|
| 11:20 - 12:10 |
Patrick Stählin, Using logical replication for fun and profit

Patrick Stählin, Aiven
Using logical replication for fun and profit
Logical replication has undergone major development in recent years. Lets have a look at various use-cases from simply replicating
data to bidirectional data-syncing and zero downtime deployments.
Target audience: General, Level: Beginner
Beschäftigt sich seit 2003 mit PostgreSQL, arbeite im PostgreSQL-Team von Aiven.
Slides
|
Aarno Aukia, Operating PostgreSQL at Scale: Lessons from Hundreds of Instances in Regulated Private Clouds

Aarno Aukia, VSHN AG
Operating PostgreSQL at Scale: Lessons from Hundreds of Instances in Regulated Private Clouds
Operating PostgreSQL at scale is one thing—doing so across highly regulated industries in private cloud environments is another.
This talk will explore how we've built and maintained large fleets of PostgreSQL instances on Kubernetes, powering critical
workloads in healthcare, finance, and government sectors.
We'll walk through architectural patterns, automation strategies, and day-two operations practices that enable us to meet
high availability, compliance, and auditability requirements. From secure multi-tenancy and declarative operations to backup,
monitoring, and lifecycle management, this session shares lessons learned from deploying and operating hundreds of PostgreSQL
clusters in environments where failure is not an option—and agility is still expected.
Whether you're building a platform for internal teams or delivering PostgreSQL as a service to external customers, this
talk offers insights into what it takes to make PostgreSQL thrive in mission-critical, cloud-native, and regulated contexts.
Target audience: General, Level: Intermediate
Aarno Aukia is Co-Founder and CTO at VSHN AG, the leading Swiss DevOps company. VSHN does software reliability engineering for
operating (web-) applications on different public and private clouds and is involved on the defensive side of web application
security. Before VSHN he was engaged with a managed security company and Google after his masters degree at ETH Zurich.
Slides
|
| 12:10 - 13:20 |
Lunch - Mensa in building 4 |
| 13:20 - 14:10 |
Bertrand Hartwig-Peillon, pgAssistant

Bertrand Hartwig-Peillon, HUG
pgAssistant
I'd like to introduce pgAssistant an OSS tool designed to help developers refine their database schema, fix inconsistencies,
and optimize their SQL queries before deployment to production.
It is using two complementary approaches for effective optimization: A deterministic approach, An AI-driven approach.
Link to pgAssistant
Target audience: Developer, Level: Beginner
postgresql lover working in a dev/sec/ops Teams on docker environments
|
Gianni Ciolli, The Why and What of WAL

Gianni Ciolli, EDB
The Why and What of WAL
The Write-Ahead-Log (WAL) is central in many PostgreSQL processes and best practices.
This talk will start with a brief history of its introduction, and then move on to some examples of the capabilities that WAL enables:
faster crash safety, efficient and restartable hot backups, physical replication, and finally logical decoding.
Target audience: General, Level: Beginner
I work at EDB as Global Vice President, Practice Lead High Availability, helping customers implement distributed architectures.
Before that, I worked at the University of Florence as a researcher in Mathematics.
I have been using Free Software for more than 25 years.
As a member of the Italian PostgreSQL User Group (ITPUG), I helped organising the first European PGDay in Prato, Italy (2008) and many editions of the the Italian PGDay.
I am an author of several editions of the PostgreSQL Administration Cookbook.
|
| 14:20 - 15:10 |
Daniel Krefl, Hacking pgvector for performance

Daniel Krefl, Sednai
Hacking pgvector for performance
In this talk I will present a modification to the popular pgvector Postgres extension for approximate nearest neighbor search. The modified extension
keeps the vector index persistent in external (Non-Postgres) memory, and pushes potential filter conditions directly into the index scan. Storage of
index and compute can also be offloaded to a GPU. I will explain in detail the inner workings of a Postgres index scan, the rational behind moving
core parts of pgvector away from Postgres, and the performance implications. I will also highlight how this modified extension finds application in
massive data processing within the framework of the AERO project for the future heterogeneous EU cloud infrastructure.
Target audience: Developer, Level: Advanced
Daniel obtained his PhD in theoretical physics from LMU Munich. His past academic positions include a Simons fellowship at UC Berkeley and a
Marie-Curie fellowship at CERN. Before deep diving into Postgres development, he researched and published in several fields, including theoretical
physics, computational biology and computer science. His current main activity: Enabling GPU acceleration of distributed databases for massive data
processing within the framework of the AERO project for the future heterogeneous EU cloud infrastructure.
Slides
|
Kaarel Moppel, Das 1x1 der Testdatengenerierung mit Postgres

Kaarel Moppel, Freelance PostgreSQL Consultant
Das 1x1 der Testdatengenerierung mit Postgres
Postgres test data generation 101
"Warum" sollte man überhaupt Testdaten generieren? Weil solche Übungen neben den offensichtlichen auch einige weniger offensichtliche Vorteile bieten.
Und wo genau lässt sich diese Phase eigentlich im App-Entwicklungszyklus integrieren?
Im Anschluss werfen wir einen Blick auf die gängigsten Techniken zur Testdatengenerierung und Leistungstests mit Postgres – die jeder, der ernsthaft
mit Postgres arbeitet, eigentlich kennen sollte:
- Von generate_series() bis LATERAL
- pgbench und die Erstellung benutzerdefinierter pgbench-Modelle
- Wie man produktionsähnliche Datenverteilungen erhält, ohne Produktionsdaten zu verwenden
- Hilfreiche Tools wie Synth & Co.
- Die Kombination von KI und Python für realistischere Daten
Abschließend geben wir Tipps zur Beschleunigung von Tests und nennen einige Fallstricke, auf die Sie achten sollten – denn die Generierung synthetischer
Testdaten bringt in der Praxis auch Einschränkungen mit sich und ist möglicherweise keine universelle Lösung.
Target audience: General, Level: Beginner
I’ve been interested in databases seemingly forever, and been working a decade plus some exclusively with PostgreSQL daily. On my spare time I enjoy
travelling, playing soccer and the great outdoors. Sometimes also blogging on Postgres at https://kmoppel.github.io/
Slides
|
| 15:10 - 15:40 |
Break & Poster Presentation - Cafeteria in building 8
During the coffee break, you will find the authors next to their posters to discuss the topics illustrated.
See Poster Gallery
- BOX FRAMEWORK: Quickly create WEB applications on top of PostgreSQL, Andrea Minetti
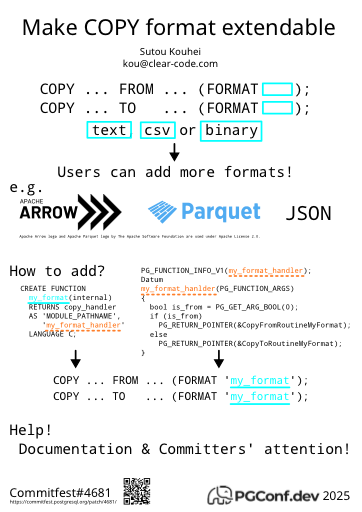
- Make COPY format extendable, Sutou Kouhei
- Incremental View Maintenance, Yugo Nagata
- I Want to Work on Postgres, But I Don’t Know Where to Start!
- PostgreSQL High Availability using Anycast and ExaBGP, Michelle von Känel
- History of the PostgreSQL Logo, Kaan Kayali and Stefan Keller
- PostgreSQL and Model Context Protocol (MCP), Stefan F. Keller
- SwissPUG – The Platform for the Swiss PostgreSQL Community
- Canonical XML, Jim Jones
|
| 15:40 - 16:30 |
Franck Pachot, Normalize or De-normalize? Relational SQL Columns or JSON Document Attributes?

Franck Pachot, MongoDB
Normalize or De-normalize? Relational SQL Columns or JSON Document Attributes?
Data modeling has progressed beyond traditional SQL Normal Forms and the unstructured storage of early NoSQL systems.
Modern applications demand flexible data models that merge normalized entities with semi-structured documents. Contemporary
SQL databases now support binary JSON columns and offer APIs similar to MongoDB (such as FerretDB for PostgreSQL). Furthermore,
NoSQL databases have evolved to allow normalized collections and provide transactional operations.
However, key questions remain: When should multiple entities be embedded within a single JSONB document? And when is it more
efficient to define a relational column instead of a sub-document attribute?
This session will clarify the distinction between physical and logical data modeling. Denormalization can enhance physical
storage by placing frequently accessed data together, while normalization is essential for maintaining logical data integrity
and preventing issues related to redundancy. By the end of this session, you will understand how to balance these two approaches
to create data models that are efficient, maintainable, and adaptable to changing application requirements.
Target audience: Developer, Level: Intermediate
Franck is a Developer Advocate at MongoDB, formerly at YugabyteDB (distributed PostgreSQL). With a long experience in database
consulting for development and operations teams and a passion for enhancing developer experience, data modeling, and performance
troubleshooting, Franck holds several certifications, including Oracle Certified Master and MongoDB Certified Associate Data Modeler,
and he is recognized as an AWS Data Hero.
Slides
|
Andreas Geppert, Tabellen vs Objekte: warum nicht einfach beides (in Postgres)?

Andreas Geppert, Zürcher Kantonalbank
Tabellen vs Objekte: warum nicht einfach beides (in Postgres)?
Objects vs tables: why not have both (in Postgres)?
In der Vergangenheit musste man mehrere, unterschiedliche Datenbankverwaltungsssyteme (DBMS) für die Verwaltung relationaler und
semistrukturierter Daten wie z.B. JSON einsetzen. Während relationale DBMS semi-strukturierte Daten nicht gut unterstützten, hatten
NoSQL-DBMS unzureichende Funktionalität für komplexe Anfragen, Transaktionen und andere DBMS-"Goodies".
Postgres begann vor mehreren Versionen, JSON zu unterstützen und erlaubt nun die Ablage von JSON-Dokumenten in Tabellen. Es bietet
ausserdem diverse Möglichkeiten, auf JSON-Dokumente zuzugreifen und sie zu verarbeiten. Diese Mechanismen sind gut in Postgres und
seine SQL-Implementierung integriert, so dass Entwickler nicht nur JSON-Dokumente verarbeiten, sondern diese auch mit der vollen
SQL-Funktionalität von Postgres weiterarbeiten können.
Target audience: Developer, Level: Beginner
Data platform architect and long-term Postgres user.
Slides
|
| 16:40 - 17:30 |
Devrim Gunduz, Know the less known about PostgreSQL
Devrim Gunduz, EDB
Know the less known about PostgreSQL
When you start using PostgreSQL, you start hearing some words: LSN, relfrozenxid, cluster, ctid, cmin, cmax, multixactid, age,
datfrozenxid, etc.
Have you ever wondered what they are, what they are used for, and how to take care of them?
In this talk, I'll give details of these less known things in PostgreSQL.
Target audience: General, Level: Beginner
Devrim Gündüz is a long-time PostgreSQL and Fedora contributor, and also working on some more open source projects. He is
responsible for the PostgreSQL YUM and ZYPP repositories for RPM based distributions.
His career started as a system administrator, and now he is working as PostgreSQL expert at EnterpriseDB.
Lives in London, UK.
|
Dirk Krautschick, Benchmarking – Eine unerwartete Reise

Dirk Krautschick, Aiven
Benchmarking – Eine unerwartete Reise
Benchmarking - An unexpected Journey
Angefangen mit einer einfachen Anfrage im Tagesgeschäft, die Leistung von PostgreSQL-DBaaS-Angeboten
verschiedener Cloud-Anbieter zu vergleichen, öffnete sich mir eine unerwartete Reise mit unerwartet mehr Aufwand,
Recherchen und Gedanken.
Dieser Vortrag beschreibt meinen Einstieg in das PostgreSQL-Benchmarking und teilt gewonnene Erfahrungen,
unerwartete Herausforderungen und wichtige Erkenntnisse.
Wir werden meine Methodik zur Entwicklung und Durchführung aussagekräftiger Benchmarks untersuchen,
einschließlich der Auswahl von Tools, der Konfigurationsoptimierung und der Workload-Modellierung, die sich
an realen Szenarien orientiert. Zu den wichtigsten Erkenntnissen gehören Strategien zur Interpretation von
Benchmark-Ergebnissen, häufige Fehlerquellen und der Einfluss von Faktoren wie Parametrisierung und
Rechenkonfigurationen.
Die Session befasst sich außerdem mit der Entwicklung von Benchmarking-Praktiken und behandelt Fragen wie:
Was unterscheidet synthetische Benchmarks von realen Leistungsmessungen? Wie wirken sich Versions-Upgrades
und neue Funktionen auf Benchmarking-Strategien aus?
Ob Datenbankadministrator, Entwickler oder Architekt – dieser Vortrag vermittelt Ihnen praktische Einblicke
und umsetzbare Techniken, um die Kunst und Wissenschaft des PostgreSQL-Benchmarkings zu meistern und das
volle Potenzial für Ihre Workloads auszuschöpfen.
Target audience: General, Level: Beginner
Dirk Krautchick has been working as a solution architect at Aiven since November 2023. As a qualified
computer scientist, he was the responsible database administrator and quality support engineer for a
manufacturer of optimization software in the aviation sector for 9 years, where he built up his know-how
in operating PostgreSQL or Oracle databases and application servers. In 2017 he decided to use his
fascination for database technologies and his skills as a consultant in - among others - the financial and
energy sector to continually deepen them. During this dynamic times, the enthusiasm and fascination for
open source from the student time returned and became priority for him. Without losing the acquired Oracle
database know-how PostgreSQL as a primary topic was expanded in terms of content, teams were recruited,
customers were trained and targeted projects were carried out. In addition to many architectural consulting
and performance tuning projects also migrations from Oracle to PostgreSQL are often the content of such
projects. In order to implement the open source and PostgreSQL strategy even more aggressively, without
losing focus on the technology a move technical sales in 2022 was inevitable - first as a sales engineer
at EnterpriseDB and now as a solution architect at Aiven.
Slides
|
| 18:00 - |
Networking Event - Bottéga Rapperswil, Doors open 18:00, Food served from 18:45
|
| Friday, 27.06.2025 |
| Time |
Room 3.008 |
Room 3.010 |
| 08:30 - 09:00 |
Registration / Coffee - Cafeteria in building 8 |
| 09:00 - 09:50 |
Josef Machytka, Building a Data Lakehouse with PostgreSQL: Dive into Formats, Tools, Techniques, and Strategies
Josef Machytka, Credativ
Building a Data Lakehouse with PostgreSQL: Dive into Formats, Tools, Techniques, and Strategies
The evolution of Data Warehouses, Data Lakes, and Data Lakehouses has been marked by many buzzwords, fluctuating trends,
and tools that often over-promised but under-delivered. While there are numerous materials on these topics, most of them
provide mostly introductory overviews and focus narrowly on a single technology. And there are even many different opinions
about what exactly is Data Lakehouse.
This talk discusses different ways how to understand this topic. It explores data formats and frameworks like Parquet,
Apache Iceberg, Delta Lake, Apache Hudi. Discusses different architectures of Data Lakehouse solutions. Also key challenges
will be addressed, such as effective Data Governance, compliance with privacy and security standards, and comprehensive data
quality checks.
Last part of the talk address current AI hype with its many promises and proposes realistic overview of real capabilities of
current Large Language Models and their use cases in Data Lakehouses.
PostgreSQL is extremely well equipped to play a major role in the current Data Lakehouse and AI boom.
Target audience: General, Level: Intermediate
30+ years of experiences with different databases, PostgreSQL 10+ years
See my LinkedIn profile
Slides
|
Matthias Grömmer, Graphdatenbanken für alle – Warum PostgreSQL mit Apache AGE eine echte Alternative zu Neo4j ist
Matthias Grömmer, CYBERTEC
Graphdatenbanken für alle – Warum PostgreSQL mit Apache AGE eine echte Alternative zu Neo4j ist
Graphdatenbanken sind derzeit einer der spannendsten Trends in der IT. Komplexe Beziehungen zwischen Daten lassen sich effizient
modellieren und analysieren. Doch oft schrecken Unternehmen vor hohen Lizenzkosten zurück – vor allem bei Lösungen wie Neo4j.
Muss das sein? Nein! Mit Apache AGE™ gibt es eine Open-Source-Alternative, die sich nahtlos in PostgreSQL integriert. In diesem
Vortrag zeigen wir, wie sich relationale und graphbasierte Modelle clever kombinieren lassen, warum openCypher als Abfragesprache
ein echter Vorteil ist und wie man mit PostgreSQL eine performante und kosteneffiziente Graphdatenbank aufbaut.
Target audience: Developer, Level: Beginner
Slides
|
| 10:00 - 10:50 |
Luigi Nardi, A benchmark study on the impact of PostgreSQL server parameter tuning

Luigi Nardi, DBtune
A benchmark study on the impact of PostgreSQL server parameter tuning
PostgreSQL, renowned for its extensibility and robust feature set, offers a wealth of server configuration parameters that can
significantly influence its performance. Most PostgreSQL users operate with default parameters, which are often not optimized
for commonly used server machine flavors. This talk is a comprehensive benchmark analysis exploring the potential performance
benefits achievable through server parameter tuning.
However, existing benchmarking frameworks often fall short in capturing the nuances of real-world deployments and the diverse
factors that influence performance. We'll examine the impact of various parameter configurations on diverse workloads,
ranging from OLTP to OLAP, and provide an analysis that highlights the performance gains and show that these depend on several
factors related to the computing environment and workloads. This talk helps database administrators and developers with actionable
insights for maximizing PostgreSQL performance through effective server parameter tuning.
Target audience: DBA, Level: Intermediate
Luigi Nardi is the founder and CEO of DBtune, a leading company driving advancements in AI, database systems, and cloud computing.
Previously an associate professor of machine learning at Lund University and a research staff at Stanford University, Luigi's
expertise centers around Bayesian methods and optimization theory and practice. Luigi's journey includes a post-doctoral
position at Imperial College London and a role as a software engineer at Murex S.A.S., following his Ph.D. program in applied
mathematics at Université Pierre et Marie Curie in Paris in 2011. Luigi is a public speaker and prolific researcher, having
co-authored more than 50 peer-reviewed papers at leading venues in machine learning and computer science.
Slides
|
Patrick Lauer, Postgres with many data: To MAXINT and beyond

Patrick Lauer, credativ
Postgres with many data: To MAXINT and beyond
In der Vergangenheit gab es Talks wie man mit PostgreSQL viele Daten, noch mehr Daten, und absurd viele Daten speichern kann.
Dieser Talk will darauf aufbauen und die Probleme und Herausforderungen aufzeigen die man findet wenn man alle Daten in
PostgreSQL hineinschaufeln will.
Vieles ist einfach mit einer handvoll Daten, aber fuehrt schnell zu Kopfschmerzen wenn man viele Daten hat.
Selbst ein naives "SELECT COUNT(*)" kann unangenehm langsam sein. Backups koennen Tage brauchen, und Restore ist aehnlich
anstrengend.
Wir werden uns die theoretischen und praktischen Grenzen ansehen, und wie man in diesem Grenzbereich arbeiten kann.
Hoffentlich gibt dieser Talk das Vertrauen dass PostgreSQL mit euren Daten mitwachsen kann, und gibt Ideen wie man mit
Performance-Problemen umgeht wenn die Datenmengen wachsen.
Target audience: DBA, Level: Intermediate
PostgreSQL supporter since many many years ago. Gentoo Linux packager of PostgreSQL and related bits. Worked with small,
large and absurdly large data in PostgreSQL.
|
| 11:00 - 11:50 |
Renzo Dani, From Oracle to PostgreSQL: A HARD Journey and an Open-Source Awakening

Renzo Dani, LogObject AG
From Oracle to PostgreSQL: A HARD Journey and an Open-Source Awakening
Migrating an enterprise application from Oracle to PostgreSQL is more than just a technical shift.
In this talk, I will share our experience at LogObject, where we transitioned from supporting only Oracle to a mixed environment
supporting both Oracle and PostgreSQL within a complex SQL-rich software base.
We will explore the challenges we faced, from implicit type casting and function overloading to JDBC quirks and SQL validation.
I will share lessons learned, the difficult choices involved in adopting PostgreSQL and insights into tools, testing strategies,
and workarounds that made this migration a success.
Of course, no migration is without trade-offs. I will also discuss our frustrations.
Beyond the technical hurdles, I will highlight the strategic benefits: faster CI pipelines, more flexible deployments and a new
found ability to innovate with an open-source database.
Target audience: General, Level: Beginner
Software developer and software architect with many years of experience. I love working in great teams.
I enjoy tackling complex processes and problems and simplifying them.
"Perfection is achieved not when there is nothing more to add, but when there is nothing left to take away." — Antoine de Saint-Exupéry
Slides
|
Dominik Frey, Ein Ansatz zur Optimierung von raumbezogenen Datenbankabfragen mit PostGIS
Dominik Frey, Camtocamp SA
Ein Ansatz zur Optimierung von raumbezogenen Datenbankabfragen mit PostGIS
An Approach to Optimize Spatial Query Performance with PostGIS
Der effiziente Umgang mit geographischen und räumlichen Daten ist ein wichtiger Faktor für die Entscheidungsfindung in Echtzeit.
In Notfallszenarien kann das Wissen, wie viele Menschen sich in einem bestimmten Gebiet aufhalten, die Katastrophenplanung erheblich
verbessern. Umfangreiche Abfragen räumlicher Daten sind jedoch rechenintensiv und erfordern ein sorgfältiges Datenbankdesign, um
aussagekräftige Resultate zeitnah zu erhalten. Die PostgreSQL-Erweiterung PostGIS, die eigens für das Handhaben von geographischen
und räumlichen Daten entwickelt wurde, bietet ein Werkzeug zur Bewältigung dieser Herausforderung. Die Kombination von PostGIS mit
einer zweckmäßigen Datenbankstruktur ermöglicht es, komplexe Szenarien effektiv anzugehen.
PostGIS ist ein Open-Source-Tool, das unter der GNU General Public License veröffentlicht wird und direkt in PostgreSQL aktiviert
werden kann, was die erweiterte Datenbank zu einer geeigneten Grundlage für unseren Anwendungsfall macht. Im Rahmen eines Projekts
für das Schweizerische Bundesamt für Bevölkerungsschutz BABS haben wir eine Web-GIS-Anwendung entwickelt, um in Katastrophenszenarien
die Anzahl der aktuell in einem Gebiet anwesenden Personen auf einer Karte zu visualisieren. Eine zentrale Anforderung an diese
Anwendung ist es, dem Benutzer die gewünschten Daten zeitnah zur Verfügung zu stellen, damit die zuständigen Stellen sofort und
effektiv handeln können. Um diese Anforderung zu erfüllen, war es unerlässlich, ein geeignetes Datenbankschema zu entwerfen und
benutzerdefinierte PostgreSQL-Funktionen zu entwickeln, um die bestmögliche Leistung zu erzielen.
In diesem Vortrag werde ich eine kurze Einführung in PostGIS geben und anschließend detaillierter auf die entwickelte
Datenbankstruktur eingehen, welche Ansätze wir in Betracht gezogen haben und wie sich diese Ansätze in Bezug auf ihre Leistung verhalten.
Target audience: Developer, Level: Intermediate
I am working as a GIS Software Engineer at Camptocamp SA. I have done my studies in the field of Computer Science. The company
I work for has specialized in the field of open source technologies and, thus, in my job as a GIS Software Engineer I regularly
use PostgreSQL as database system.
Slides
|
| 11:50 - 13:00 |
Lunch - Mensa in building 4 |
| 13:00 - 13:50 |
Pavlo Golub, Customizing the Wordle Game Experience with PostgreSQL

Pavlo Golub, CYBERTEC
Customizing the Wordle Game Experience with PostgreSQL
Discover the endless possibilities of PostgreSQL as a gaming platform by harnessing its ability to customize the Wordle game.
Explore how PostgreSQL empowers developers to redefine the game experience through three core entities:
- The available word set. Do we want to allow all words or only popular and well-known ones? Do we want to limit a set
to some topic, e.g., IT-slang terms, or geographically limited? Should we restrict a guessing word length to 5
characters, or can we vary? For which languages it's better to use shorter or longer words?
- The standard guess-checking function returns yellow and green position marks. But what if we will use another score
function, like Levenshtein distance? Or even bigram/trigram positions instead of single characters?
- And the move acceptance function. Should it check the guess only against the initial word set? Or allow any word in
the target language? Or allow any word restricted by simple regular expression?
Gain insights into curating word dictionaries, enabling support for non-English languages, and implementing innovative gameplay
mechanics. With PostgreSQL's advanced features and extensibility, attendees will unlock the potential to create unique
and engaging gaming experiences. Join me as we explore the transformative power of PostgreSQL in the world of Wordle.
Target audience: General, Level: Beginner
I am a PostgreSQL contributor and co-organizer of PostgreSQL Ukraine User Group, as well as Senior Developer and Expert
at Cybertec. I am the author of pgxmock library and scheduling solution for PostgreSQL written in Go called pg_timetable.
Also I am a maintainer of pgwatch2 monitoring solution.
Slides
|
Andrew Farries, Postgres schema migrations using the expand/contract pattern

Andrew Farries, Xata.io
Postgres schema migrations using the expand/contract pattern
Learn how to do Postgres schema changes without breaking dependent applications by leveraging the expand/contract pattern.
pgroll is a new open-source migration tool for Postgres that keeps multiple versions of a schema live during a migration,
helping you roll out database schema changes without downtime. Postgres schema changes often pose significant challenges
to developers, particularly when striving for zero downtime migrations.
There are many things that can go wrong:
- Schema changes breaking client applications
- Unexpected table locking causing downtime
- Human mistakes causing data loss
This talk presents a new approach to schema changes using an ‘expand/contract’ pattern where multiple versions of a database
schema are maintained during the migration, allowing old and new versions of client applications to run side-by-side during an
application rollout. Each version of the application sees the version of the database schema with which it is designed to work.
The talk covers the ideas behind this approach, and the challenges to be overcome such as:
- The use of Postgres views to present multiple versions of an underlying table.
- Backfilling data between old and new schema versions.
- Techniques to avoid unexpected table locking during migrations.
Finally we introduce pgroll, an open-source tool that puts these ideas into practice and we show how it can be used to facilitate
safe application rollouts across database schema changes.
Target audience: Developer, Level: Intermediate
Andrew has over 10 years experience building developer tools, with a particular focus on database tools in cloud-native environments.
He currently works at Xata.io, building a serverless data platform powered by Postgres.
|
| 14:00 - 14:50 |
Alessandro Cerioni, Making sense of Waze traffic data with Python, TimescaleDB-PostGIS and JavaScript

Alessandro Cerioni, Etat de Genève
Making sense of Waze traffic data with Python, TimescaleDB-PostGIS and JavaScript
Waze is a free navigation app for smartphones, allowing its users (aka "Wazers") to report various kinds of traffic
and road hazards. Besides, the app sends Wazers' speed and location to Waze servers, resulting in a vast amount of
real-time data, which Waze aggregates and makes available through a dedicated HTTP API. Since March 2023 the Canton of Geneva
is collecting Waze data, within the frame of the "Waze for Cities Data Program". Once per minute (= data refresh
frequency), a Python program downloads JSON documents from the Waze API and store them into an S3-based Data Lake. Work is
in progress to extract valuable insights from the collected data (> 15M records/month, for a coverage of around 1 550
square kilometers), in order to gain a better knowledge on road traffic and to support the decision-making process. More
specifically, an ETL has been developed, which moves data from S3 to a TimescaleDB-PostGIS database. Data is aggregated in
both time and space in-database, using Geneva's road network segments as spatial units. A web application powered by
React, MapLibre GL JS and Plotly allows end-users to visualize aggregated data, exposed by a FastAPI backend which fetches
(Geo)JSON documents and Mapbox Vector Tiles straight from the database. Given the large volume of data to deal with, the main
key challenges are: (1) performance optimization, e.g. by using database indexes and finding a good trade-off between batch
and on-the-fly data processing; (2) addressing the evolving needs of end-users with a relational and yet flexible data model.
Target audience: Developer, Level: Intermediate
Alessandro Cerioni received a Ph.D. in Theoretical Physics from the University of Bologna in 2011. After three years of
post-doctoral research, he enrolled in a 1-year continuing education program in Computer Science & ICT at INSA-Lyon.
From November 2016 to March 2020, he has been working at the Métropole de Lyon as Data Scientist and Product Owner of the
data.grandlyon.com platform. Since April 2020 he works at the État de Genève as Data Scientist, with a focus on geodata.
He is also a member of the Swiss Territorial Data Lab team, with which he
collaborates part-time.
Slides
|
Grant Fritchey, Query Performance Monitoring For The Absolute Beginner

Grant Fritchey, Redgate Software
Query Performance Monitoring For The Absolute Beginner
You may know that your database is slow, or, you may be told that there are performance problems in the database. However,
how do you know where the performance problems are? Which queries are running the slowest? Why are they running slow?
This session will take you through the fundamental tools that are built right into PostgreSQL that can help you answer
all these questions. We'll start with using queries against the Cumulative Statistics Systems. We'll begin an
exploration of explain plans. Setup and guidance for how all these tools work will be provided along the way. You can
finally know which queries are slow, and why they are slow.
Target audience: General, Level: Beginner
Grant Fritchey is a Data Platform MVP and AWS Community Builder with over 30 years’ experience in IT, including time
spent in support and development. Grant works with multiple data platforms including PostgreSQL and SQL Server, as well
as multiple cloud platforms. He has also developed in Python, C#, and Java. Grant writes books for Apress and Simple-Talk,
including the new book "Introduction to PostgreSQL for the Data Professional." Grant presents at conferences and
user groups, large and small, all over the world. He joined Redgate Software as a product advocate in January 2011.
|
| 14:50 - 15:10 |
Break - Cafeteria in building 8 |
| 15:10 - 16:10 |
Lightning Talks: Vik Fearing & Possibly you? - Room 3.008
Lightning Talks
Moderation:Vik Fearing
In this session, several people are given the opportunity to give a short presentation of max 5 minutes. These can be on any topic,
including PostgreSQL, but excluding commercial advertising. We are happy to hear about new ideas, work in progress, calls for papers,
or notices of upcoming changes.
If you would like to participate, please add your name and topic to the list at the registration desk or send them by email.
If you want to present slides, these need to be mailed as a PDF to lt@pgday.ch before 14:00.
- Josef Machytka, Boldly Migrate to PostgreSQL with credativ-pg-migrator
- Pavlo Golub, Kudos for the rest of us
- Audrius Meškauskas, Efficient Web Development with SeaORM and PostgreSQL.
- Franck Pachot, NULL is unknown (yet)
- Raphael Debinski, pgstat_snap – a (very) poor man’s ASH for PostgreSQL
- Luigi Nardi, ML for Systems and Systems for ML
- Johannes Graën, Travel Romania efficiently - Graph search with CTEs
- Michael Hegyi, PG patching with GitLab pipelines
- Marlene Retterer, Postgres and Web3
- Kaarel Moppel, Postgres on spot VMs?
- Laurenz Albe, The tower of Babel
Slides
|
| 16:10 - 16:30 |
Closing: Stefan Keller - Room 3.008
Stefan Keller, OST
Professor for information systems, founder and head of Geometa Labs. Keller is a member of the Swiss PGDay board and involved in various open source projects such as PostGIS and QGIS and open data initiatives, e.g. OpenStreetMap. Besides, he is generally interested in geographic data and their visualization as well as in the the integration of open source and proprietary solutions (e.g. QGIS and ArcGIS).
Professor für Informationssysteme sowie Leiter und Gründer des Geometa Labs. Ist u.a. Mitglied des Swiss PGDay OK und engagiert in verschiedenen Open Source Projekten (z.B. PostGIS und QGIS) und Open Data (v.a. OpenStreetMap). Zudem interessieren ihn allgemein Geodaten und Geovisualisierung sowie die Integration von Open Source und proprietärer Software (z.B. QGIS und ArcGIS).
Slides
|
all times are in CEST / UTC+2.
The schedule is subject to change.
Location
The OST (Eastern Switzerland University of Applied Sciences,
Campus Rapperswil) is located directly at
the upper Zurich lakeshore with a view on the alpine foothills
(
Map - Address: Oberseestrasse 10, 8640 Rapperswil, Switzerland).
A map of the campus with buildings and rooms can be found
here. The registration is in the cafeteria in
building Nr. 8. This is also the place where you can meet
and get coffee during the day.
How to get there
The premises of the OST are right beside the train station of Rapperswil (southern exit,
look for the signs). We recommend you therefore to use public transportation. It is possible,
however, to reach the University
by car.
- By train:
The ride from Zurich Main Station to Rapperswil takes about 30 minutes by train (S5/S7/S15).
- By car:
The nearest public parking place is about 10 minutes walking from the OST - see also
the local parking directing system. The best parking possibility is at the Children Zoo
in Rapperswil, see
PDF ("Südquartier, Lido": number 7 on the map).
On the campus, there are only very few parking places for a maximum of 2 hours.
Where to stay
If you are staying overnight and are looking for a hotel, there are several nearby accommodations in a variety of price ranges.
Here are some suggestions:
Networking event
See details under networking event.
Job board
Looking for people or a new job? There's a whiteboard near the registration desk where sponsors,
companies and conference attendees can post potential job openings, resumes, company profiles and more.
If you hang around during the breaks, you may be able to connect with each other.
We ask our sponsors to have a presence there.
Ease of access
The campus is accessible for wheelchairs.
Code of conduct
Swiss PGDay 2025 is dedicated to providing a harassment-free conference
experience for everyone.
We do not tolerate harassment of Swiss PGDay 2025 participants in any form.
Sexual language and imagery is not appropriate for any conference venue, including exhibition booths,
talks, chat groups and social events around Swiss PGDay 2025. Conference
participants violating these rules may be sanctioned or expelled from the conference without a refund
at the discretion of the Swiss PGDay 2025 conference organizers.
Harassment includes offensive verbal comments related to gender, sexual
orientation, disability, physical appearance, body size, race, religion,
displaying sexual images in public spaces, deliberate intimidation, stalking,
following, harassing photography or recording, sustained disruption of talks or
other events, inappropriate physical contact, and unwelcome sexual attention.
Participants asked to stop any harassing behavior are expected to comply
immediately.
If a participant engages in harassing behavior, the Swiss PGDay 2025 conference
organizers may take any action they deem appropriate, including ejection from the conference with no
refund. If you feel that you are being harassed, notice that someone else is being harassed, or have any
other concerns, please contact a Swiss PGDay 2025 Staff Member immediately.
Swiss PGDay 2025 Staff will be happy to help participants contact the police,
provide escorts, or otherwise assist those experiencing harassment to feel safe for the duration of the
conference.
Thank you for your help in making Swiss PGDay 2025 fun and enjoyable for
everyone!
Local points of contact:
Organizing committee
pgday@swisspug.org
Venue contact number: +41 58 257 47 46
Emergency services: 112.
If the complaint is about an organizer or staff members of the event, you may
contact a SwissPUG Board member directly. You may also contact the
PostgreSQL community code of conduct committee
if you prefer an outside organisation, in which case the conference organizers and
SwissPUG will commit to assisting the CoC committee to the best of their abilities.
Privacy
Swiss PGDay operates a "Red Lanyard" scheme that is designed to help you maintain your privacy at our
events. When you collect your badge upon arrival at the conference, you will be able to select either a
red or blue lanyard. Choosing a red lanyard will indicate to the event organisers and other attendees that
you do not wish to have your photograph taken and posted on social media or on other public sites.
We will make every effort to honour your wishes, and we ask all attendees to do the same. It is, however,
a 'best effort' system and sometimes a red lanyard may not be spotted before a picture is posted publicly.
In cases where this happens, please reach out to either the person who posted the picture or to the
conference organisers to request that the picture be removed.
Financial disclosure
The costs of Swiss PGDay are covered by the income from our sponsors and the registration fees.
We try to keep the costs as low as possible for both parties and offer special rates for students
and underprivileged to enable as many people as possible to attend. Our budget is calculated to break even.
Operating losses and profits resulting from deviations from the budget will be managed by the
Swiss PostgreSQL Users Group. Profits will be
reinvested in the next year's Swiss PGDay. No member of the organizing committee will receive any
payment for their work, other than free attendance and an invitation to the speakers' dinner.
Donations
You can support us financially by donating to the Swiss PostgreSQL Users Group
association. There are no obligations associated with donations. Please mention in a short notice if the donation shall be treated
anonymously or not. Donations can be sent via bank transfer to IBAN: CH11 0900 0000 6152 7599 2,
BIC: POFICHBEXXX Account holder: Swiss PostgreSQL Users Group, 3110 Münsingen
Community event
Responsible for the Swiss PGDay is the
Swiss PostgreSQL Users Group (SwissPUG). The event does comply
with the PostgreSQL
Community Conference Recognition guidelines and the use of the
trademark "PGDay" is granted by
PostgreSQL Europe.
Talk selection process
All submissions are looked at and considered by the program committee by reading abstracts, titles
and submission notes. The program committee members each vote on every submission with a score of
1 through 9. We abstain from voting (i.e. vote NULL, not 0) on submissions by ourself or coworkers.
We try hard not to have repeated speakers and to promote diversity. The selection committee reserves
the right to invite keynote speakers outside the CfP. All members need to agree on a proposed keynote talk.
Program committee (alphabetic order)
Organization committee (alphabetic order)
Past events
Swiss PGDay 2024
Swiss PGDay 2023
Swiss PGDay 2022
Swiss PGDay 2021
Swiss PGDay 2020
Swiss PGDay 2019
Swiss PGDay 2018
Swiss PGDay 2017 (German)
Swiss PGDay 2016 (German)
Background picture CC BY-SA 3.0 Roland zh. Thank you!
Portrait Placeholder CC BY-SA 4.0 Greasemann.
Networking Event
On Thursday evening, 26 June 2025, all participants of the Swiss PGDay are invited to the networking event at Club Bottéga.
Here you can network and exchange ideas in an informal setting. Club Bottéga opens for us at 18:00. The buffet will be opened at 18:45.
The cost for food, non-alcoholic drinks, beer and wine will be covered by Swiss PGDay. To simplify logistics, please bring the voucher you
receive at conference check-in and wear your badge.
Coming from the conference venue, you will reach Club Bottéga at Neue Jonastrasse 72 after a 10-minute walk:
Map


Speakers Dinner
On Wednesday evening, 25 June 2025, the evening before the conference, we invite all speakers of the Swiss PGDay to our Speakers Dinner.
We will meet at the Vinoteca Mi Tierra, Alpenstrasse 7, 8640 Rapperswil near the centre of Rapperswil.
Map.
You can arrive from 18:45 for drinks. Dinner will be served at around 19:30.
Please register at info@pgday.ch and select one of the menus below to let us know if you can attend:
-
Meat: Salad with empanada, a plate of beef with vegetables and potatoes, dessert.
-
Vegitarian: Mixed salad, stuffed peppers with vegetables and potatoes, dessert.
If you have any special dietary requirements, please let us know.




















Networking Event
On Thursday evening, 26 June 2025, all participants of the Swiss PGDay are invited to the networking event at Club Bottéga. Here you can network and exchange ideas in an informal setting. Club Bottéga opens for us at 18:00. The buffet will be opened at 18:45. The cost for food, non-alcoholic drinks, beer and wine will be covered by Swiss PGDay. To simplify logistics, please bring the voucher you receive at conference check-in and wear your badge.
Coming from the conference venue, you will reach Club Bottéga at Neue Jonastrasse 72 after a 10-minute walk: Map